PyCon 2013 was an excellent conference bringing together Python’s vast, diverse, and technically excellent community. I had the opportunity to visit the whole conference including the sprint days.
Magnitude
The size of the community seems well reflected by the number of attendees that PyCon US attracts: the limit of 2,500 attendees was reached on 2013-02-02, about 1 month prior to the conference. This should be about 500 attendees more than in 2012 when they exceeded their planned capacity of 1,500 ending up with 2,000 IIRC.
It was very nice to see that the organization is growing along with the task: everything ran very smoothly, a lot of detailed changes over last year, some for better, some for worse (Remember: if you want to improve, you need to change, and the means you need to accept set backs to learn.)
Diversity
Yes, there was this FUBAR situation regarding a “code of conduct” violation. I think too many people who have not been at PyCon have contributed to the turmoil already so I’ll refrain from commenting.
I was happy to hear that PyLadies (and everybody else working on the diversity of the community) could see their efforts showing excellent results: around 20% of all participants were women (or girls). I had the impression on the first day of the conference that more women were around than usually on tech conferences.
But not only that, we also had:
- a wide range of ages: from kids, to students, to way more senior people
- very business and very relaxed, alternative people (Plone RV, anyone?)
- visitors from all over the world
I had to ponder a bit why this actually makes me happy: the diversity shows me that what we do is important to everyone and does not need to be either obscure and geeky or shirt-and-tie business.
We can have a community where you can be geeky and nerdy, do business, and feel like a human being. How great is that? Conferences always tend to be very intense environments, somewhat “from outer space”. Combined with travelling overseas for almost two weeks, having a human environment just makes it so worthwhile and a bit more sustainable.
To everybody who did not have an absolutely great experience personally: I’m empathatic and I hope next PyCon will be better for you. A lot has been said about the code of conduct and the organizers definitely pay a lot of attention to it. Nevertheless: 2,500 people stuffed into a few rooms over almost a week will cause friction here and there. If I should encounter a similar situation myself I will hopefully be able to apply some of the experience as a bystander and: stay calm, be friendly, and help defusing situations.
Technical excellence
There isn’t much you can do to get more sophisticated technical people talking about programming into the same spot compared to PyCon. Maybe DEFCON, or USENIX, or other more orthogonally oriented spots. But for practicality this is just it.
I recommend you visit pyvideo.org and go through the recorded videos of all sessions. It’s always a good idea to listen to what Raymond Hettinger has to say. And Guido, of course.
Sprinting
I felt very productive during the sprints: I started out sitting in a room with Nate Aune, Jeff Forcier, and some others, talking about deployment things. I worked a bit on our deployment utility batou trying to soften some rough edges and gather feedback from others.
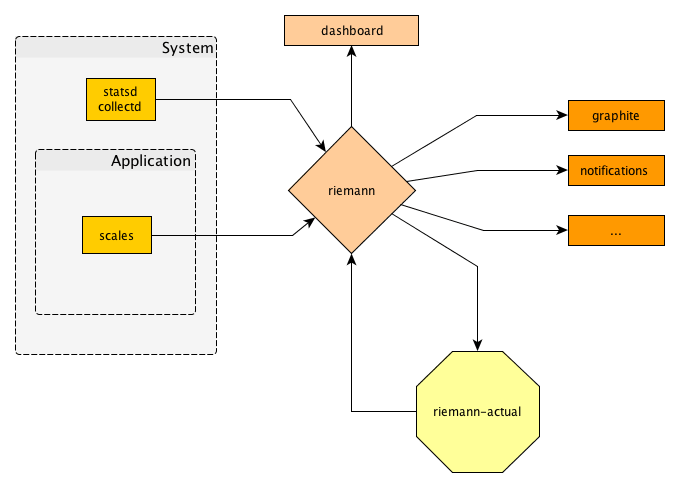
However, I also had the PyPI mirror client software on my radar. As we are operating one of the official mirrors (the F mirror) I was fed up by the constant breakage that the existing pep381client experienced everywhere. I sat down, refactored, and lo and behold! a bandersnatch appeared. This is a full rewrite that can be used with the existing mirror data and is much more reliable and – in the case of error – easier debug and recover.
Sponsoring
gocept also was a silver sponsor for PyCon. We already sponsored PyCon in 2012, but this year we:
- did not insert more stuff into the attendee bag (it’s way too heavy already anyways)
-
did set up a booth to become approachable and get to talk to people
Our product (the Flying Circus) is in use for consulting clients but still on its way to become a product that you can just use by registering and providing payment details. Operations as a service is a very dynamic space today and we had some good opportunities to try to explain what we envision and where we think existing IaaS and PaaS models are aiming at the wrong thing. If you’re interested in this kind of thing, then visit our homepage and sign up to our newsletter and we’ll keep you updated.
PyCon has been a very sponsor-friendly place, especially for small businesses. It’s always a hassle to bring a lot of stuff half around the globe, but the environment was perfect to just bring some banner and flyers and talk to people strolling around.
2014
So next year, PyCon US will actually be PyCon North America, as the conferences moves to Montreal. Besides making this a much shorter trip I’m also looking forward to some new cultural impressions.
")
")
