Since we have a strong history in web development, but also were involved in operating web applications we developed, the DevOps movement hit our nerves.
Under the brand name “Flying Circus” we are establishing a platform respecting the DevOps principles.
A large portion of our day-to-day work is dedicated to DevOps related topics. We like to collaborate by sharing ideas and work on tools we all need to make operations and development of web applications a smooth experience. A guiding question: how can we improve the operability of web applications?
A large field of sprintable topics comes to our mind:
Logging
Enable web application developers to integrate logging mechanisms into their apps easily. By using modern tools like Logstash for collecting and analyzing of the data, operators are able to find causes performance or other problems efficiently.
Live-Debugging and Monitoring
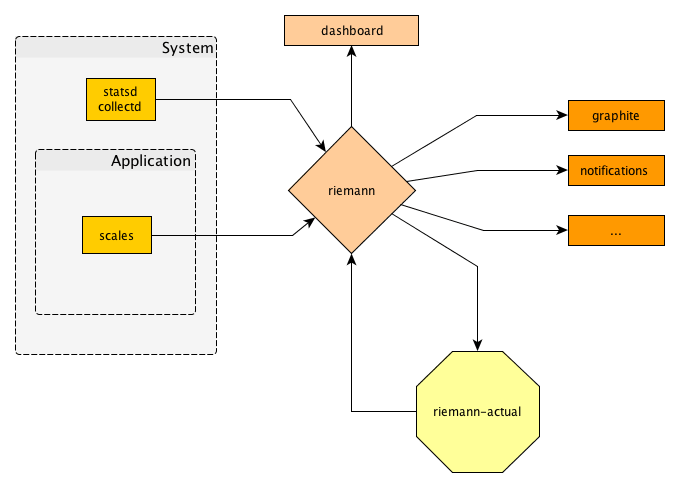
Monitoring is a must when operation software. At least for some people (including ourselves), Nagios is not the best fit for DevOps teams.
Deploying
We always wanted to have reproducable automated deployments. Coming from the Zope world, started with zc.buildout, we developed our own deployment tool batou. More recently upcoming projects, such as ansible, and tools (more or less) bound to cloud services like heroku.
Backup
After using bacula for a while, we started to work on backy, which aims to work directly on volume files of virtual machines.
and more…
Join us to work on these things and help to make DevOps better! The sprint will take place at our office, Forsterstraße 29, Halle (Saale), Germany. On September, 20th we will have a great party in the evening.
If you want to attend, please sign up on http://www.meetup.com/DevOps-Sprint/events/191582682/.
Accomodation
For your stay in Halle, we can recommend the following Hotels: “City Hotel am Wasserturm”, “Dorint Hotel Charlottenhof”, “Dormero Hotel Rotes Ross”. For those on budget, there is the youth hostel Halle (http://halle.djh-sachsen-anhalt.de/). Everything is in walking distance from our office.