In the coming week we will deploy an extensive OS update to our production environment which (right now) currently consists of 41 physical hosts running 195 virtual machines.
Updates like this are prepared very carefully in many small steps using our development and staging setups that reflect the exactly same environment as our production systems in the data center.
Nevertheless, we learned to expect the unexpected when deploying to our production environment. This is why we established the one/few/many paradigm for large updates. The remainder of this post talks about our scheduling mechanism to determine which machines are updated at what point in time.
Automated maintenance scheduling
The Flying Circus configuration management database (CMDB) keeps track of times that are acceptable to each customer for scheduled maintenance. When a machine determines that a particular automated activity will be disruptive (e.g. because it makes the system temporarily unstable or reboots) then it requests a maintenance period from the CMDB based on the customers’ preferences and the estimated duration of the downtime Customers are then automatically notified what will happen at what time.
This alone is too little to make a large update that affects all machines (and thus all customers) but it’s the mechanical foundation of the next step.
Maintenance weeks
When we roll out a large update we rather add additional padding for errors and thus we invented the “maintenance week”. For this we can ask the CMDB to proactively schedule relatively large maintenance windows for all machines in a given pattern.
Here’s a short version of how this schedule is built when an administrator pushes the “Schedule maintenance week” button in our CMDB (all times in UTC):
- Monday 09:00 – automation management, monitoring, and binary package compilation get updated
- Monday 13:00 – the first router and one storage server are updated
- Monday 17:00 – internal test machines (our litmus machines) and a small but representative set of customer machines that are marked as test environments get updated
- Tuesday 17:00 – the remainder of customer test machines, up to 5% of untested production VMs, and 20% of the storage servers are updated
- Wednesday 17:00 – 30% of the production VMs get updated and 30% of the storage servers are updated
- Thursday 17:00 – the remaining production VMs and storage servers get updated
- Saturday 09:00 – KVM hosts are updated and rebooted
- Saturday 13:00 – the second router is updated
Once the schedule has been established, customers are informed by email about the assigned slots. An internal cross-check ensures that all machines in the affected location do have a window assigned for this week.
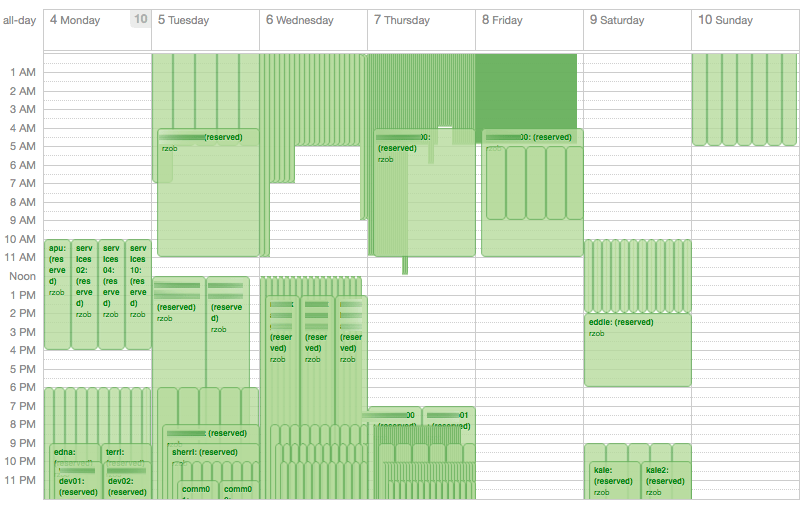
This procedure causes the number of machines that get updated rise from Monday (22 machines) to Thursday (about 100 machines). Any problems we find on Monday we can fix on a small number of machines and provide a bugfix to avoid the issue on later days completely.
However, if you read the list carefully you are probably asking yourself: Why are customer VMs without tests updated early? Doesn’t this force customers without tests to experience outages more heavily?
Yes. And in our opinion this is a good thing: First, in earlier phases we have smaller numbers of machines to deal with. Any breakage that occurs on Monday or Tuesday can be dealt with more timely than if unexpected breakage occurs on Wednesday or Thursday where many machines are updated at onces. Second, if your service is critical then you should feel the pain of not having tests (similar to pain that you experience if you don’t write unit tests and try to refactor). We believe that “herd immunity” will give you a false sense of security and rather have unexpected errors occur early and clearly visible so they can be approached with a good fix instead of hiding them as long as possible.
We’re looking forward to our updates next week. Obviously we’re preparing for unexpected surprises, but what will they have in stock for us this time?
We also appreciate feedback: How do you prepare updates for many machines? Is there anything we’re missing? Anything that sounds like a good idea to you? Let us know – leave a comment!